Последовательный анализ mSPRT для сокращения времени A/B тестов
Опубликовано: Апрель 16, 2025
Последовательный анализ A/B теста на основе отношения вероятностей со смесью (mSPRT -- mixture Sequential Probability Ratio Test) - это статистическая методология для последовательного тестирования, позволяющая проверять поступающие данные эксперимента в любой момент времени при этом, контролируя ошибку I рода. В отличие от традиционных тестов с фиксированным размером выборки, последовательные тесты позволяют раннее завершение при накоплении достаточных доказательств.
Когда такой подход может быть особенно полезен для онлайн-проектов? Например, в следующих случаях:
- Вам нужно определить статзначимый рост или падение какой-либо метрики (например, количество ошибок после релиза новой версии сайта или падение конверсий в вашем тесте на определенный уровень дельты) в реальном времени, т.е. как можно быстрее и получать соответствующую индикацию для быстрого принятия решений.
- Вы проводите тест рекламных компаний и хотите как можно быстрее определить победиля, чтобы не тратить бюджет на неэффективные рекламные каналы.
- Вы проводите тест, который может негативно повлиять на пользовательский опыт и хотите минимизировать время экспозиции пользователей к потенциально плохому варианту.
- Вы хотите ускорить процессы A/B тестирования, там где это возможно, например, где предполагаемый эффект может быть достаточно заметным, чтобы быстрее принимать решения.
- И т.д.
Основы теории SPRT
Основа данного подхода была заложена в таких известных работах, как "On the problem of the most efficient tests of statistical hypotheses" опубликованной Нейманом и Пирсоном в 1933 году и работе Абрахама Вальда, профессора математической статистики Колумбийского университета "The Sequential Analysis" изданной в виде книги в 1947 году, где он представил метод SPRT. Конечно были и другие работы, но книга Вальда благодаря своей полноте стала хорошей основой для изучения и понимания метода. Книга была переведена на русский язык и издана в 1960 году ("Последовательный анализ").
В свой книге Вальд представил обоснование метода SPRT, математические формулировки для расчета некоторых его параметров и примеры его применения в различных областях.
Вальд разбирает метод отношения правдоподобий для принятия решения в процессе тестирования простой нулевой гипотезы $H_0: \theta = \theta_0$ против простой альтернативной $H_1: \theta = \theta_1$. Этот подход позволяет контролировать ошибки I и II рода в условиях "подглядывания" за результатами теста.
Как бы это ни парадоксально звучало с точки зрения классической теории проверки гипотезы с фиксированным горизонтом - в методе SPRT мы наоборот смотрим на результаты теста по мере поступления данных и принимаем решение о его завершении или продолжении.
Понятие последовательной проверки хода эксперимента
В своей работе Вальд объясняет:
Метод последовательной проверки гипотезы $H$ можно изложить следующим образом. Устанавливается некоторое правило, которым руководствуются при принятии решения на каждом этапе эксперимента (при $m$-м испытании, где $m$ — любое целое число):
- Принять гипотезу $H$;
- Отклонить гипотезу $H$;
- Продолжать эксперимент и провести дополнительное наблюдение.
На основе первого наблюдения принимается одно из трёх вышеуказанных решений. Если принимается первое или второе решение, проверка завершается. Если принимается третье решение, производится второе наблюдение. На основе двух наблюдений вновь принимается одно из трёх возможных решений. Если принимается третье решение, выполняется третье наблюдение и т. д. Процесс проверки продолжается до тех пор, пока не будет принято первое или второе решение. Количество наблюдений $n$, необходимых для принятия решения, является случайной величиной, поскольку оно зависит от исхода наблюдений.
Для простой нулевой гипотезы $H_0: \theta = \theta_0$ против простой альтернативы $H_1: \theta = \theta_1$, основа критерия, а именно отношение правдоподобия на этапе $n$ определяется как:
$$ \Lambda_n = \frac{\prod_{i=1}^n f(x_i; \theta_1)}{\prod_{i=1}^n f(x_i; \theta_0)}, $$
где $f(x_i; \theta)$ — функция плотности вероятности наблюдения $x_i$ при параметре $\theta$ (правдоподобие).
Отношение правдоподобия $\Lambda_n$ используется для принятия одного из трёх решений на этапе $n$:
- Принять $H_0$, если $\Lambda_n > A$;
- Принять $H_1$, если $\Lambda_n < B$;
- Продолжить эксперимент, если $B \leq \Lambda_n \leq A$. где $A$ и $B$ — заранее заданные пороговые значения (границы), определяющие критерий принятия решений в последовательной проверке.
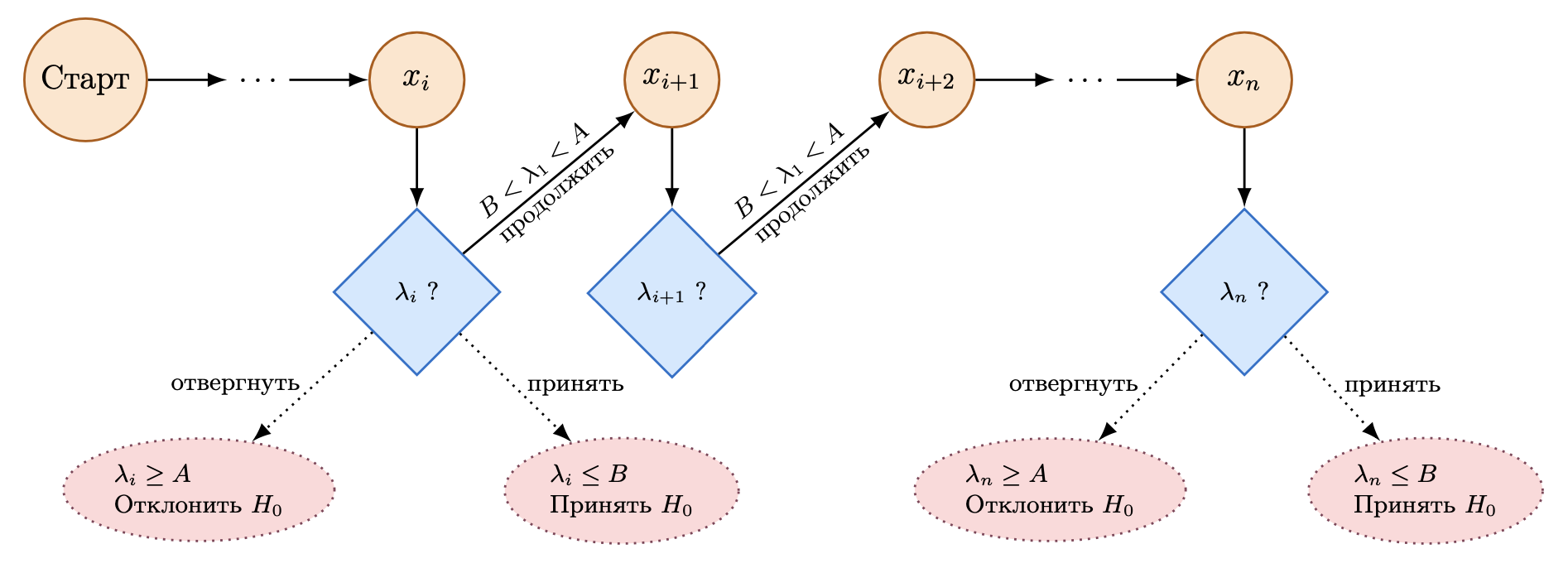
Рис.1 Схема примера последовательной проверки гипотез. В отличие от классических критериев с фиксированным объёмом выборки (фиксированный горизонт), последовательный критерий позволяет принимать решение практически после каждого наблюдения: либо принять гипотезу $H$, либо отвергнуть её, либо продолжить выборку на основе подсчитанной величины $\lambda_n$ (отношения правдоподобия). В случае, если $\lambda_n$ попадает в область принятия гипотезы $H$, то мы принимаем гипотезу $H$. Если $\lambda_n$ попадает в область отклонения гипотезы $H$, то мы отвергаем гипотезу $H$. Если $\lambda_n$ попадает в область неопределённости, то мы продолжаем выборку.
Величины $A$ и $B$ выбираются таким образом, чтобы обеспечить заданные уровни ошибок первого и второго рода. В своей книге Вальд выводит формулы для приблизительного расчета этих границ:
$$ A \approx \frac{1-\beta}{\alpha}, \quad B \approx \frac{\beta}{1-\alpha}, $$
где:
$\alpha$ = P(отклонить $H_0 \mid H_0$ истинна) — уровень ошибки I рода,
$\beta$ = P(принять $H_0 \mid H_1$ истинна) — уровень ошибки II рода.
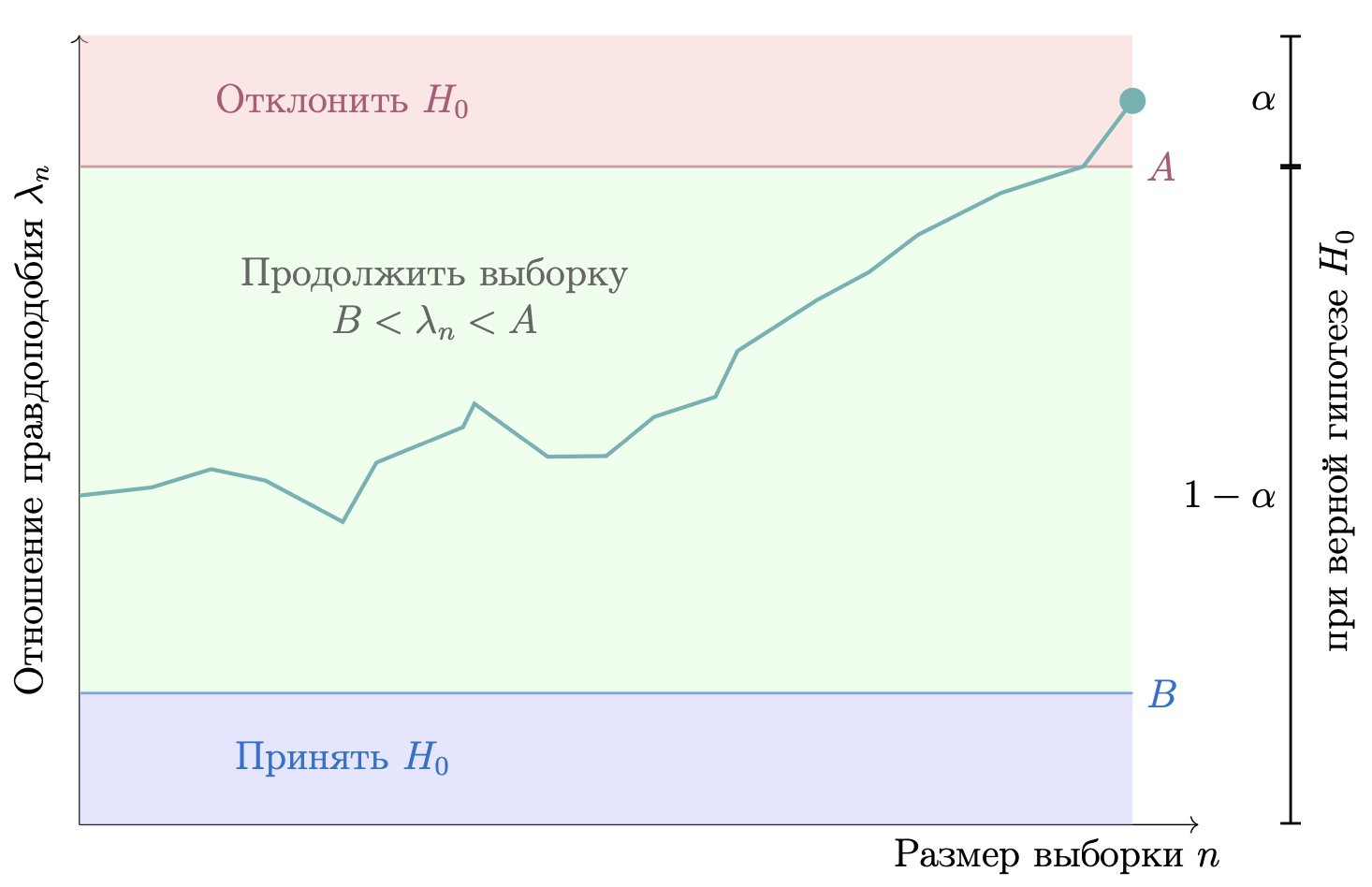
Рис.2 Визуальное представление последовательного теста SPRT. Зеленая линия представляет пример траектории отношения правдоподобия $\lambda_n$ по мере увеличения размера выборки. Когда траектория пересекает одну из границ (A или B), принимается решение
Ограничения простого SPRT и преимущества mSPRT для онлайн-проектов
Несмотря на свою эффективность, простой SPRT имеет два очевидных ограничения, которые затрудняют его применение в реальных условиях:
- Ограничение одной выборки. Простой SPRT предполагает, что данные поступают из одной выборки, что делает его прямое использование неприменимым для задач, где необходимо сравнивать две или более выборки (например, в A/B тестах).
- Простота дизайна альтернативной гипотезы. Простой SPRT требует, чтобы альтернативная гипотеза $H_1$ была задана в виде фиксированного значения параметра $\theta_1$. Это ограничивает его гибкость, так как в реальных задачах альтернативная гипотеза часто имеет более сложный характер.
Для преодоления этих ограничений был разработан метод mSPRT (mixture Sequential Probability Ratio Test), который расширяет возможности SPRT за счёт добавления "смеси" к отношению правдоподобий и решает тем самым следующие задачи:
- Поддержка нескольких выборок. mSPRT позволяет работать с несколькими выборками, что делает его подходящим для задач сравнения, таких как A/B тесты.
- Гибкость альтернативной гипотезы. Вместо фиксированного значения параметра $\theta_1$, mSPRT использует смесь распределений для моделирования альтернативной гипотезы. Это позволяет учитывать неопределённость в параметрах и делать тест более универсальным.
Благодаря этим улучшениям и возможностям, mSPRT стали применять, как платформы для A/B тестирования (например, Optimizely), так и ряд крупных компаний в сфере онлайн проектов.
Метод mSPRT
Применение последовательного тестирования в A/B тестах потребовало расширения SPRT для работы с данными из двух выборок. Подход был представлен Джохари и соавторами в работе "Peeking at A/B Tests: Why it matters, and what to do about it" (2017), который стал известен, как последовательный анализ на основе отношения вероятностей со смесью (Mixture sequential probability ratio test).
Основная его идея заключается в следующем: поскольку это двусторонний тест, обозначим $H_0 : \theta = \theta_0$ и $H_1 : \theta \ne \theta_0$ как нулевую и альтернативную гипотезы соответственно и определим $H$ как смешивающее распределение по $\Theta$ с плотностью $h$, и пусть $f_{\theta}$ будет плотностью данных с параметром $\theta$ (правдоподобие), тогда смешивание $H$ по пространству параметров $\Theta$ означает применение вероятностного распределения к возможным значениям тестируемого параметра:
$$\Lambda_n^{H, \theta_0} = \int_{\Theta} \prod_{i=1}^n \frac{f_\theta(X_i)}{f_{\theta_0}(X_i)}h(\theta)d\theta.$$
Здесь $h(\theta)$ — это функция плотности смеси (везде положительная), которая контролирует распределение альтернативной гипотезы, проверяемой в отношении правдоподобия. Таким образом, mSPRT позволяет учитывать неопределённость в параметрах и делать тест более универсальным. Но пока это по прежнему одновыборочный тест.
Правило принятия решения в mSPRT
Правило принятия решения в mSPRT аналогично правилу в простом SPRT, но использует смешанное отношение правдоподобия $\Lambda_n^{H, \theta_0}$. На каждом шаге $n$ принимается одно из двух решений:
- Отклонить $H_0$, если $\Lambda_n^{H, \theta_0} \ge 1/\alpha$.
- Продолжить эксперимент, если $\Lambda_n^{H, \theta_0} < 1/\alpha$.
Здесь $\alpha$ — это заданный уровень ошибки I рода. Тест продолжается до тех пор, пока не будет выполнено условие для отклонения $H_0$. Важно отметить, что в этой формулировке mSPRT нет явной границы для принятия $H_0$, как в классическом SPRT (граница $B$). Тест продолжается до тех пор, пока не будет достаточно доказательств для отклонения $H_0$ на уровне значимости $\alpha$. Если тест завершается без отклонения $H_0$ (например, по достижении максимального размера выборки или времени), то $H_0$ не отклоняется.
Выбор порога $1/\alpha$ для отношения правдоподобия гарантирует контроль ошибки I рода на уровне $\alpha$ с помощью стандартных мартингальных методов (Siegmund 1985).
Рисунок 3 представляет собой концептуальную иллюстрацию процесса mSPRT:
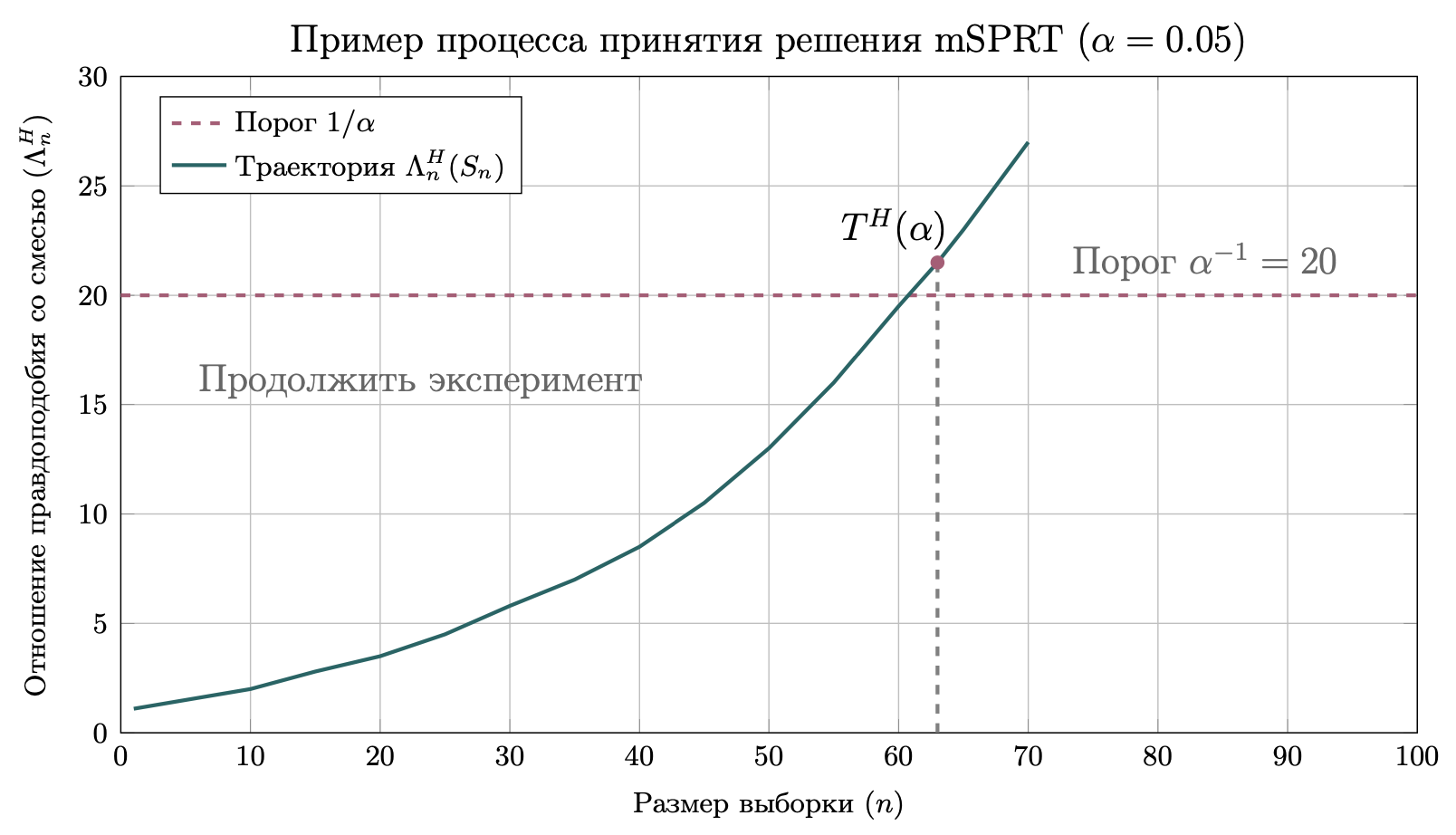
Рис. 3 Иллюстрация mSPRT. Отношение правдоподобия со смесью $\Lambda_n^H$ отслеживается по мере увеличения размера выборки $n$. Тест останавливается и отклоняет $H_0$, когда траектория впервые пересекает порог $\alpha^{-1}$. В этом примере при $\alpha=0.05$ порог равен 20, и момент остановки $T^H(\alpha)$ наступает при $n=63$.
mSPRT для A/B тестирования
Остается вопрос, как вышеизложенное применить к двухвыборочному A/B тесту? В A/B тесте мы сравниваем две вариации друг с другом. Т.е. мы наблюдаем две независимые последовательности i.i.d. $X$ и $Y$ из групп, получающих опыт A и B соответственно. В случае биномиальной метрики (используются для моделирования бинарных исходов, таких как клики, конверсии и т.д.) сравниваются две гипотезы:
$$ H_0: \theta := p_B - p_A = 0 \quad \text{против} \quad H_1: \theta \neq 0. $$ где $p_A$ и $p_B$ — это вероятности успеха (конверсии) в группах A и B соответственно.
Соответственно в случае непрерывной метрики (например, выручка) чаще всего статистикой выступает среднее значение: $$ H_0 : \theta := \mu_B - \mu_A = 0 \quad \text{против альтернативной гипотезы} \quad H_1 : \theta \neq 0. $$
Джохари в своей работе "Peeking at A/B Tests" посвященной методу mSPRT пишет:
Чтобы получить mSPRT для A/B-тестирования, нам нужно определить отношение правдоподобия со смесью $\tilde{\Lambda}_n^{H, \theta_0}$ для экспериментов с двумя вариантами как функцию данных $X_1, \ldots, X_n, Y_1, \ldots, Y_n$.
Начнем с рассмотрения нормальных данных. В этом случае заметим, что для любых $\mu^A$ и $\mu^B$, $Z_n = Y_n - X_n \sim N(\theta, 2\sigma^2)$. Таким образом, мы можем просто применить одновариантный mSPRT к последовательности ${Z_n}$; это приводит к следующему определению:
$$ \tilde{\Lambda}_n^{H, \theta_0} = \sqrt{\frac{2\sigma^2}{2\sigma^2 + n\tau^2}} \exp{ \left(\frac{n^2 \tau^2 (\bar{Y}_n - \bar{X}_n - \theta_0)^2}{4\sigma^2 (2\sigma^2 + n\tau^2)}\right)}, $$ где $\theta_0$ — это разница средних при нулевой гипотезе.
Для биномиальных метрик предлагается такое решение:
Для бинарных данных мы рассматриваем эксперимент с одной вариацией, где каждое наблюдение представляет собой пару $(X_n, Y_n)$, и $\theta$ неизвестно, но $\mu$ фиксировано. Отношение правдоподобия со смесью в этом случае сводится к отношению правдоподобия со смесью, основанному на любой достаточной статистике для $\theta$ в этой модели с одной вариацией. Мы отмечаем, что для любого $\mu$, $\bar{Y}_n - \bar{X}_n$ является асимптотически достаточной статистикой с асимптотическим распределением $N(\theta, V_n/n)$, где:
$$ V_n = \bar{X}_n(1 - \bar{X}_n) + \bar{Y}_n(1 - \bar{Y}_n). $$
Это распределение напоминает распределение достаточной статистики $\bar{Z}_n$ в нормальном случае с $2\sigma^2 = V_n$, и поэтому по аналогии мы используем следующий mSPRT:
$$ \tilde{\Lambda}_n^{H, \theta_0} = \sqrt{\frac{V_n}{V_n + n\tau^2}} \exp {\left( \frac{n^2 \tau^2 (\bar{Y}_n - \bar{X}_n - \theta_0)^2}{2V_n (V_n + n\tau^2)} \right)}, $$ где $\theta_0$ — это разница вероятностей успеха при нулевой гипотезе (если $V_n = 0$, то полагаем $\tilde{\Lambda}^{H, \theta_0} = 1$).
Так как аппроксимации верны только при больших $n$, точная валидность не всегда достигается, но моделирование показывает, что приблизительный контроль ошибки I рода обеспечивается при малых $\alpha$, когда для отклонения $H_0$ требуются большие размеры выборки.
Таким образом для нормального распределения и биномиальных метрик мы имеем алгебраическое выражение для отношения правдоподобия со смесью, которое позволяет нам использовать mSPRT для последовательного анализа A/B тестов, переложив соответствующее уравнение и правило для принятия решения на программный код.
На практике однако возникают следующие вопросы:
- Как выбрать тау ($\tau$)?
- Что делать, если мы хотим фиксировать статзначимый сдвиг метрики только на определенную дельту и больше, игнорируя меньшие значения?
- Как быть в случае не нормального распределения, например, имеющего длинный хвост?
Скорее всего эти вопросы не имеют однозначного ответа, но если порассуждать, то можно сказать что:
- Тау ($\tau$) в определенном смысле определяет априорный размер эффекта, который мы закладываем в алтернативную гипотезу. Одним из способов подбора тау я вижу симулирование данных близких к вашим реальным данным и подгонка тау по ним на основании ваших знаний о возможных размерах эффекта.
- Если мы хотим фиксировать подъем или падение метрики на определенный уровень дельты, например для алертов количества ошибок при релизе новой версии сайта, то один из вариантов - это небольшая модификация уравнения и определение альтернативной двусторонней гипотезы с помощью границ $[\theta_0-\delta, \theta_0+\delta]$. Двусторонней - потому что мы, как правило хотим замерять движение в обе стороны, и потому что мы по-прежнему используем подход смешивания, хотя уже в другой форме, который позволяет нам это делать.
- Джохари так поясняет ситуацию с нормальным и не нормальным распределением:
"Для нормальных данных мы используем эмпирическую оценку для $\sigma^2$; симуляции показывают, что это не влияет на ошибку I рода при малых $\alpha$. Кроме того, существуют некоторые непрерывные метрики, такие как «выручка», где распределение имеет тяжелый правый хвост, что делает нормальную модель непригодной. Для таких случаев смесь отношений правдоподобия вычисляется в рамках более общей модели, которая может учитывать эту асимметрию."
Таким образом последовательный анализ с помощью метода mSPRT представляет собой интересный и достаточно гибкий инструмент для ускорения A/B тестирования за счет раннего детектирования уже накопленных доказательств. Его математическая основа - это отношения правдоподобия со смесью. Он позволяет учитывать неопределённость в параметрах, является достаточно настраиваемым, что делает его полезным инструментом для практики A/B тестирования.