Нюансы GrowthBook: биномиальные метрики (конверсия)
Опубликовано: Май 22, 2025
В данной статье рассматриваются принципы проведения A/B тестов для биномиальных метрик с использованием платформы GrowthBook. Затрагивается математическая основа байесовского подхода, применяемого для оценки результатов эксперимента, создания таблиц фактов и метрик. Рассматриваются нюансы работы с метрикой конверсий и интерпретации соответствующих результатов.
Disclaimer: Данная статья не является пособием по установке и первичной настройки GrowthBook, и в целом она скорее предполагает, что читатель уже имеет опыт использования данной платформы. Она не является учебным материалом на основе официальной документацией GrowthBook. Для получения актуальной информации и рекомендаций по использованию платформы можно обратится к официальной документации на сайте https://docs.growthbook.io/.
Небольшое введение в GrowthBook
Для тех, кто не еще не очень наслышан о данном инструменте, напомним: GrowthBook — это открытая платформа для экспериментов и управления функциональными флагами, которая позволяет применять канареечное развертывание, проверять гипотезы и в целом реализовывать культуру принятия решений на основе данных.
Ключевые возможности GrowthBook:
- Проведение A/B тестов с различными типами метрик
- Байесовский и фреквентистский подходы к анализу данных
- Визуализация и интерпретация результатов
- Управление функциональными флагами
- Интеграция с различными источниками данных
GrowthBook предоставляет два основных статистических движка для анализа экспериментов:
- Байесовский движок — использует байесовский подход для оценки вероятности превосходства одной вариации над другой, в том числе при желании, учитывая априорные знания.
- Фриквентистский движок — использует классический подход с p-value и доверительными интервалами.
Как и у любой платформы у GrowthBook есть свои достоинства и некоторые недостатки и ряд особенностей и нюансов. В этой статье мы сосредоточимся на некоторых нюансах байесовского движка (актуальных на момент написания статьи), попробовав применить его на неординарном примере A/B теста с биномиальной метрикой (конверсия), а именно когда мы имеем мало наблюдений, и нас интересует именно вероятность того, что вариант B (тест) лучше варианта A (контроль). Такой пример лучше позволит увидеть и сравнить подход GrowthBook с альтернативным решением.
Мотивация
Почему такой небольшой набор данных? Основная идея заключается в том, что мы хотим посмотреть, можем ли мы проводить в GrowthBook такие тесты. Кто-то может подумать, что таких кейсов не бывает, но данный пример взят из реального A/B теста и представлены реальные результаты. История очень простая - вы запускаете дорогую рекламу, тестируя, к примеру, два креатива, и параллельно смотрите на цену клика или конверсии, если она дорогая - останавливаем тест, имея на руках всего пару целевых пользователей в каждой группе наблюдений. Да, такой тест нельзя считать совсем корректным, но как-то проанализировать его результаты все же нужно.
Таким образом метрикой успеха в данном эксперименте мы будем считать попользовательскую конверсию перехода по рекламе.
Для каждого пользователя $i$ определим бинарный результат:
$$ Y_i = \begin{cases} 1, & \text{если } k_i > 0 \\ 0, & \text{иначе} \end{cases} $$
где $k_i$ — количество целевых действий (например, кликов) для пользователя $i$.
Эта метрика позволяет оценить долю пользователей, которые совершили хотя бы одно целевое действие:
$$ \hat{p} = \frac{1}{N} \sum_{i=1}^N Y_i $$
Т.е. наша биномиальная (или бернуллиевская) случайная величина — это индикаторная переменная, принимающая значение 1 (пользователь сконвертировался) или 0 (пользователь не сконвертировался).
Обозначим $X$ — бернуллиевскую случайную величину: $X \sim \text{Ber}(p)$. Тогда:
$$ E[X] = p , \quad \text{Var}(X) = p(1 - p) $$
Настройка эксперимента в GrowthBook
Теперь давайте немного напомним, как работает A/B тестирование в GrowthBook. Для проведения A/B теста в GrowthBook необходимо выполнить несколько шагов по настройке эксперимента.
1. Создание проекта
GrowthBook позволяет создавать проекты для организации экспериментов. Каждый проект может содержать несколько экспериментов, которые могут быть связаны между собой. Если вы еще не создали проект, то вам нужно это сделать.
2. Создание источника данных (меню Data Sources)
Предположим, что у вас уже есть проект и вы запустили A/B тест для биномиальной метрики. Нам нужно настроить получение данных о пользователях и их действиях в эксперименте.
Меню Data Sources предназначено для настроики параметров, связанных с подключением к хранилищу данных и SQL запросом, который возвращает все нужные данные о пользователях участвующих в эксперименте(ах). GrowthBook поддерживает интеграцию с различными хранилищами данных, включая PostgreSQL, MySQL, BigQuery и другие.

Для настройки источника данных необходимо: 1. Создать подключение к базе данных 2. Определить SQL-запрос для получения данных об экспериментах
Пример запроса для получения данных эксперимента (Experiment Assignment Query):
SELECT
user_id,
dt as timestamp,
exp_id as experiment_id,
variation as variation_id,
revenue,
orders,
is_conv
FROM
experiments
Этот запрос извлекает данные экспериментов, где:
user_id— идентификатор пользователя (зарезервированный параметр в GrowthBook)timestamp— время события (зарезервированный параметр)experiment_id— идентификатор эксперимента (зарезервированный параметр)variation_id— идентификатор вариации (0, 1, 2, ...) (зарезервированный параметр)revenue,orders,is_conv— метрики для анализа

3. Создание таблиц фактов (меню Fact Tables)
Fact tables в GrowthBook позволяют объединить несколько метрик в одном SQL-запросе. Это повышает производительность и упрощает настройку метрик, поэтому данный метод является рекомендуемым, хотя есть и альтернативный легаси метод c отдельным SQL запросом для каждой метрики.
Пример запроса для таблицы фактов:
SELECT
user_id as user_id,
dt as timestamp,
revenue,
orders,
is_conv
FROM
experiments
WHERE exp_id='exp1'
4. Создание метрик
После настройки таблицы фактов здесь же необходимо создать метрики для анализа.
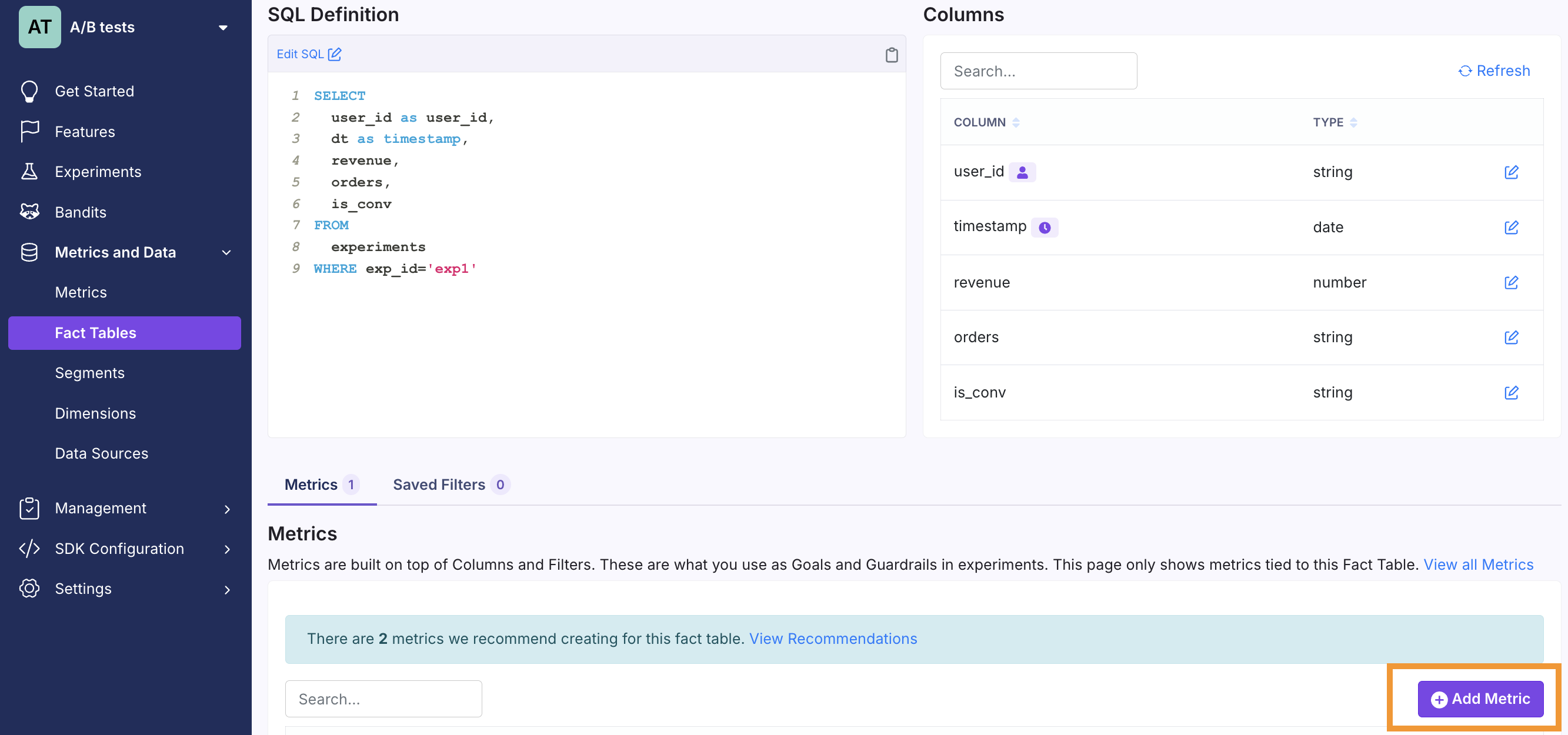
Для биномиальных метрик выбирается тип «доля» (Proportion). Обратите внимание, что возможно вам придется скорректировать настройки, чтобы GrowthBook начал показывать результаты эксперимента при небольшом количестве конверсий.

5. Создание эксперимента
Создаем или редактируем эксперимент в GrowthBook. В данном случае мы хотим использовать байесовский подход для анализа данных. GrowthBook позволяет выбрать между байесовским и фриквентистским подходами.
Для нашей метрики конверсии мы выберем неинформативный приор с нормальным распределением, который не влияет на результаты.

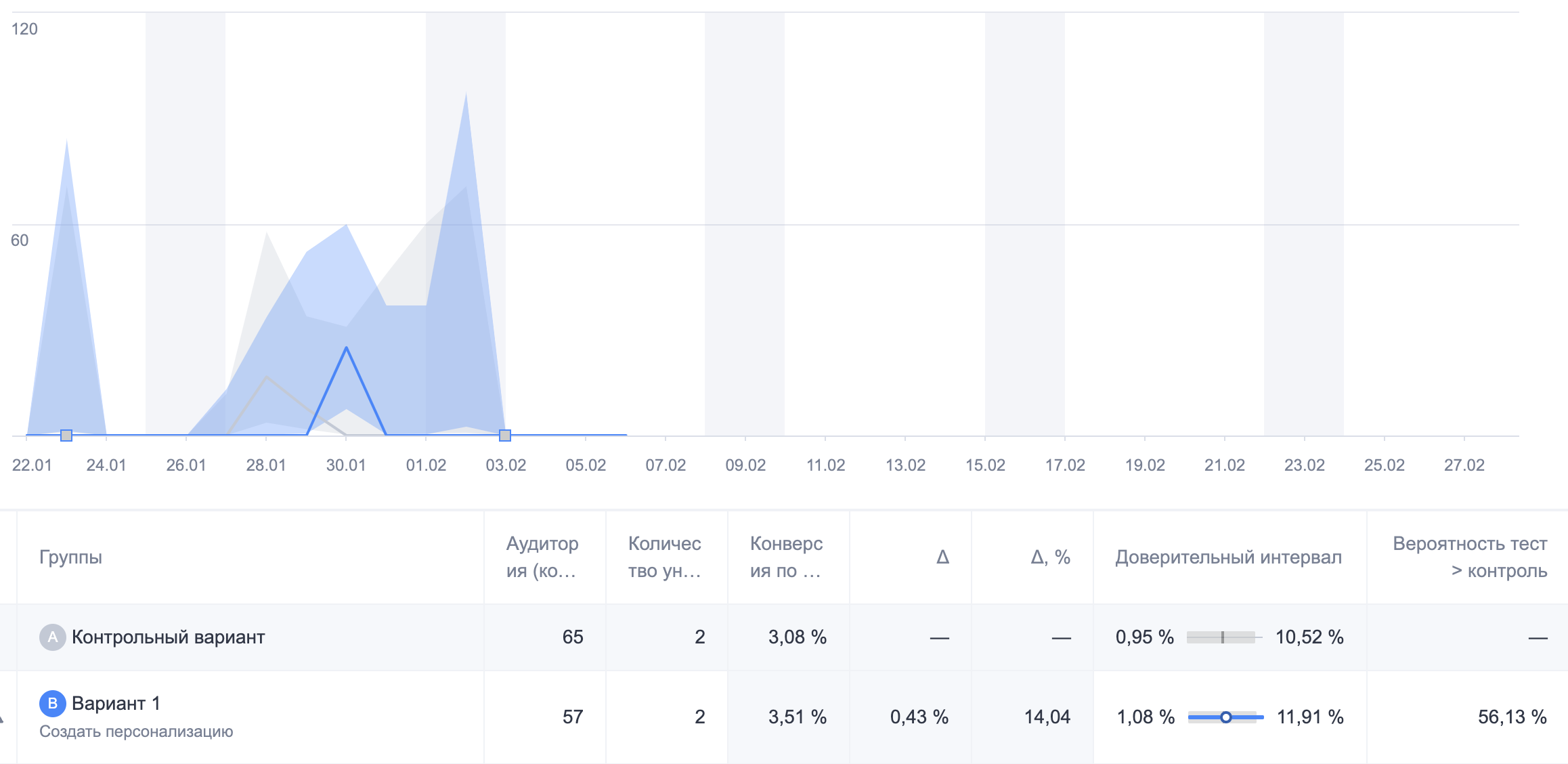
6. Результат эксперимента
Если данные эксперимента уже доступны, мы можем их просмотреть, включая точечные оценки, доверительные интервалы и вероятность превосходства (Chance to Win).
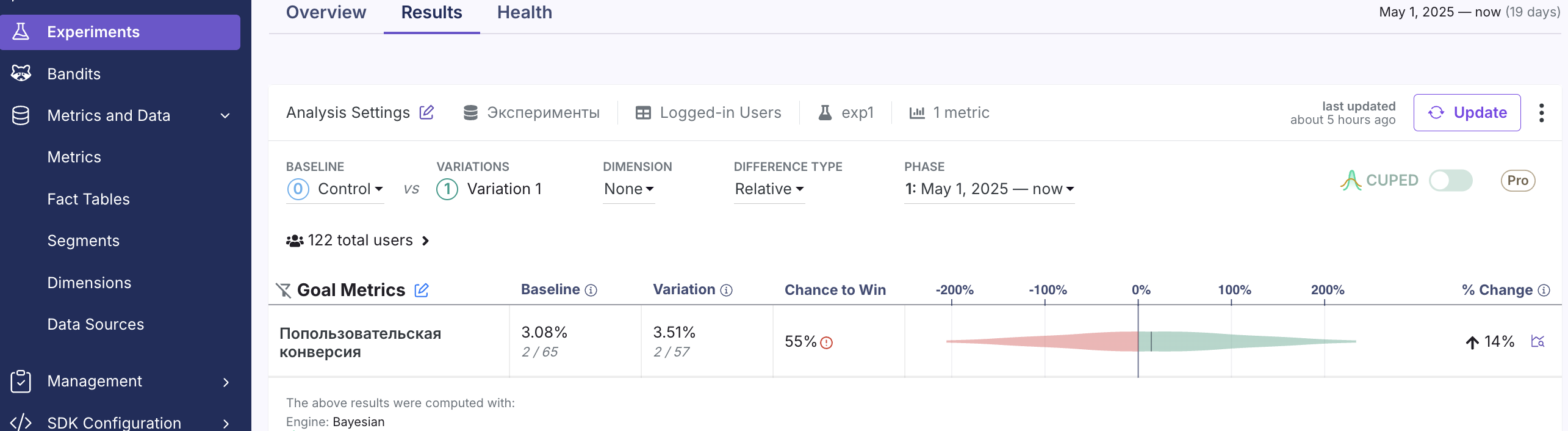
Результат данного эксперимента:
- Вариант A: 2 конверсии на 65 пользователей (3.08%)
- Вариант B: 2 конверсии на 57 пользователей (3.51%)
- Вероятность B>A: 55%
Математическая основа биномиальных метрик в GrowthBook
Мы хотим ответить на вопрос, как мы получили эти цифры для вероятности превосходства (Chance to Win) и как GrowthBook оценивает результаты эксперимента. Для этого мы рассмотрим математическую основу биномиальных метрик, используемых в GrowthBook.
Growthbook доки озвучивают следующие моменты применения Байесовского подхода:
We specify the following prior
$$ \Delta_{\text{prior}} \sim N(\mu_{\text{prior}}, \sigma_{\text{prior}}^{2}). $$
This information is represented by the prior mean $\mu_{\text{prior}}$ and the prior variance $\sigma_{\text{prior}}^{2}$. The prior mean is your best guess for the treatment effect before the experiment starts. The prior variance determines your confidence in this best guess. A small prior variance corresponds to high confidence, and vice versa. GrowthBook's default prior is an improper prior (i.e., $\sigma_{\text{prior}}^{2}=\infty$) that has no impact.
...
These priors are normally distributed and our effect estimates above are asymptotically normally distributed via the Central Limit Theorem. Therefore, combining them to compute our posterior beliefs, which will themselves be normally distributed, we get the following mean and variance for our posterior effect estimates:
$$ \Delta_{\text{posterior}} = \frac{\frac{\mu_{\text{prior}}}{\sigma_{\text{prior}}^{2}} + \frac{\hat{\Delta}}{\hat{\sigma}^2_{\Delta}}}{\frac{1}{\sigma^2_{\text{prior}}} + \frac{1}{\hat{\sigma}^2_{\Delta}}} , \quad \sigma^2_{\text{posterior}} = \frac{1}{\frac{1}{\sigma^2_{\text{prior}}} + \frac{1}{\hat{\sigma}^2_{\Delta}}} $$
Chance to Win is the percentage of the posterior that is greater than 0 in favor of the treatment variation
$$ CTW = 100\% \times (1 - \Phi_{\text{posterior}}(0)), $$
where $\Phi_{\text{posterior}}$ is the CDF of the distribution $N(\Delta_{\text{posterior}}, \sigma^2_{\text{posterior}})$.
В этом описании байесовского подходя для оценки результатов A/B тестов в Growthbook есть пару интересных нюансов:
- Расчет принимает во внимание не исходное распределение, а оценочный эффект.
- Исходя из этого и того, что нет отдельного упоминания биномиальных метрик, можно сделать вывод, что расчет биномиальных метрик осуществляется через аппроксимацию нормальным распределением.
- Если ваше исходное распределение не нормальное и не биномиальное, то вам приходится надеяться на асимптотическую состоятельность ваших выборок.
Давайте проверим, правильно ли наше предположение, рассчитав вероятность превосходства (Chance to Win) для нашего примера A/B теста, используя формулы из GrowthBook.
Шаг 1: Рассчитаем точечные оценки и стандартные ошибки
Для вариации A:
$$ \begin{align} \hat{p}_A &= \frac{2}{65} = 0.0308 \quad (3.08\%) \\ \hat{\sigma}^2_A &= \frac{\hat{p}_A(1-\hat{p}_A)}{n_A} = \frac{0.0308 \times 0.9692}{65} \approx 0.000459 \\ \hat{\sigma}_A &= \sqrt{0.000459} \approx 0.0214 \end{align} $$
Для вариации B:
$$\begin{align} \hat{p}_B &= \frac{2}{57} = 0.0351 \quad (3.51\%) \\ \hat{\sigma}^2_B &= \frac{\hat{p}_B(1-\hat{p}_B)}{n_B} = \frac{0.0351 \times 0.9649}{57} \approx 0.000594 \\ \hat{\sigma}_B &= \sqrt{0.000594} \approx 0.0244 \end{align}$$
Шаг 2: Рассчитаем эффект и его дисперсию
Эффект (абсолютная разница):
$$ \hat{\Delta} = \hat{p}_B - \hat{p}_A = 0.0351 - 0.0308 = 0.0043 $$
Дисперсия эффекта:
$$\begin{align} \hat{\sigma}^2_{\Delta} &= \hat{\sigma}^2_A + \hat{\sigma}^2_B = 0.000459 + 0.000594 = 0.001053 \\ \hat{\sigma}_{\Delta} &= \sqrt{0.001053} \approx 0.0325 \end{align}$$
Шаг 3: Рассчитаем апостериорное распределение
С неинформативным приором:
$$\begin{align} \Delta_{\text{posterior}} &= \hat{\Delta} = 0.0043 \\ \sigma^2_{\text{posterior}} &= \hat{\sigma}^2_{\Delta} = 0.001053 \\ \sigma_{\text{posterior}} &= 0.0325 \end{align}$$
Шаг 4: Рассчитаем вероятность превосходства
$$\begin{align} P(B > A) &= 1 - \Phi\left(\frac{0 - 0.0043}{0.0325}\right) \\ &= 1 - \Phi(-0.132) \\ &= 1 - 0.45 \\ &= 0.55 \text{ или } 55\% \end{align}$$
где $\Phi$ — кумулятивная функция нормального распределения.
Таким образом, мы получили вероятность превосходства 55%, что совпадает с результатами GrowthBook на скришоте выше. Это подтверждает, что GrowthBook использует аппроксимацию нормальным распределением для биномиальных метрик и рассчитывает вероятность превосходства на основе апостериорного распределения.
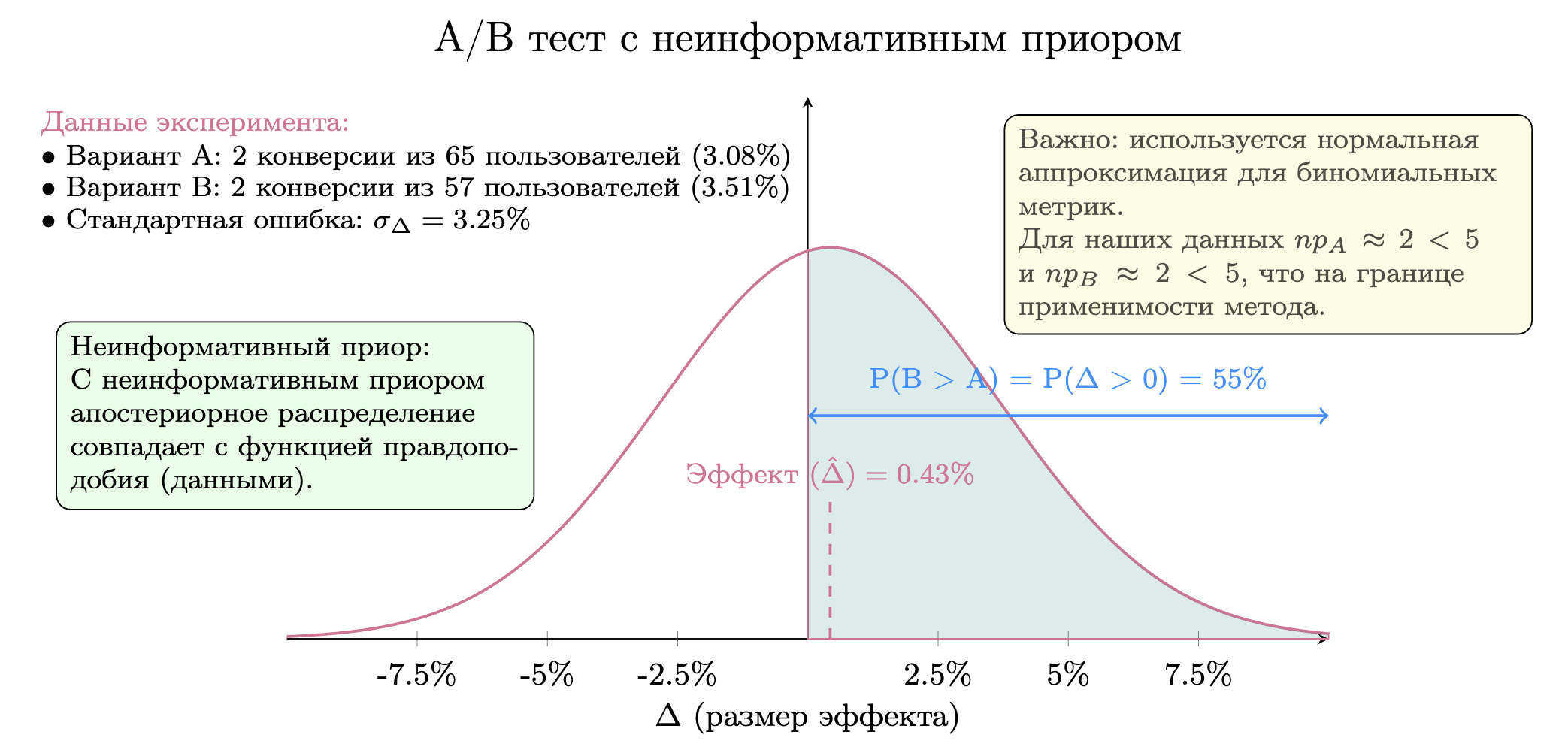
Визуализация A/B теста с неинформативным приором. При использовании неинформативного приора, апостериорное распределение полностью определяется данными эксперимента. Закрашенная область представляет вероятность того, что вариант B превосходит контрольный вариант A (55%).
Сравнение с точным (неапроксимированным) расчетом для биномиальной метрики
Как же будет отличаться результат, если использовать неапроксимированное биномиальное распределение? Для точного расчета мы можем использовать либо метод Монте-Карло, либо алгебраические формулы для биномиального распределения. Так получилось, что данный тест проводился с использованием платформы для A/B тестирования от Яндекса - Varioqub, которая использует именно алгебраический метод для расчета вероятности превосходства. Поэтому результат мне известен заранее, а именно 56.13%. Ознакомиться с формулой, по которой происходит расчет можно на странице документации Varioqub Расчет метрик методом Байеса.
Как мы видим, результат отличается от 55% на 1.13%. Разница не очень большая, но она хорошо иллюстрирует, что в случае малых выборок, нормальная аппроксимация может давать некоторые погрешности.
Данный пример, на мой взгляд, хорошо иллюстрирует почему результаты в некоторых A/B тестах могут различаться в разных платформах или при разных методах расчета. Например, в случае с Varioqub, который используют точный расчет биномиального распределения, в то время как GrowthBook использует нормальную аппроксимацию. Это может привести к различиям в результатах, особенно в случае малых выборок или редких событий.
Интерпретация результатов
При интерпретации результатов A/B тестов в GrowthBook следует учитывать:
- Вероятность превосходства — показывает вероятность того, что вариация B лучше вариации A. В нашем примере эта вероятность составляет 55%, что означает, что мы не можем с уверенностью сказать, что вариация B превосходит вариацию A.
- Размер эффекта — в нашем примере эффект составляет 0.43 процентных пункта или 14% относительного лифта.
- Доверительные интервалы — широкие доверительные интервалы указывают на высокую неопределенность в оценке эффекта. В нашем примере стандартная ошибка эффекта (0.0325) значительно превышает сам эффект (0.0043), что указывает на высокую неопределенность.
Размер выборки
Для биномиальных метрик с низкими конверсиями (как в нашем примере) требуются большие размеры выборок для достижения статистической значимости. В нашем примере:
- Размер выборки недостаточен для обнаружения небольшого эффекта (0.43 процентных пункта)
- Для более надежных выводов можно использовать инструменты планирования размера выборки до начала эксперимента
Заключение
GrowthBook предоставляет мощный и гибкий инструмент для проведения A/B тестов. Байесовский подход, используемый в GrowthBook, позволяет получить интуитивно понятную интерпретацию результатов в виде вероятности превосходства.
Однако при работе с биномиальными метриками в GrowthBook важно учитывать:
- Правильную настройку источников данных, таблиц фактов и метрик - проверяйте получаемые точечные оценки с помощью SQL-запросов вне GrowthBook.
- Ограничения нормальной аппроксимации для малых выборок и редких событий
- Необходимость достаточного размера выборки, особенно для метрик с низкой конверсией
- При использовании информативного приора, учитывайте, что по умолчанию в GrowthBook он задается в относительных величинах, а не в абсолютных.