Формализованное представление процесса AB-тестирования
Опубликовано: Август 07, 2025
В этом документе предлагается теоретически обоснованная модель AB-тестирования, которая избегает избыточности, сохраняя при этом статистическую строгость. Подробно описывается математическое формулирование, даются сопутствующее объяснения и визуальные иллюстрации для более удобного восприятия основных аспектов процесса AB-тестирования.
Формулировка модели
Структура данных
Для каждого пользователя $i = 1, \ldots, n$ в процессе A/B тестирования мы наблюдаем:
- $Z_i \in {A, B}$: индикатор принадлежности к группе (A или B)
- $X_i$: наблюдаемая метрика (например, доход, клики и т.д.)
- $Y_i$: наблюдаемая дополнительная метрика (опционально, используется в первую очередь для построения ratio-метрик, см. далее по тексту)
Соответственно, датасет, который мы рассматриваем, может иметь вид: $$ \{ (X_i, Y_i, Z_i) \; | \; i = 1, ..., n \} $$
Агрегированные метрики
Определим множества: $$ A = \{ i : Z_i = A \}, \quad B = \{ i : Z_i = B \} $$
Пусть $n_A = |A|$, $n_B = |B|$
Среднее по группе: $$ \text{Mean}_A = \frac{1}{n_A} \sum_{i \in A} X_i, \qquad \text{Mean}_B = \frac{1}{n_B} \sum_{i \in B} X_i $$
Конверсия (CR):
$$
\text{CR}_A = \frac{1}{n_A} \sum_{i \in A} \mathbb{I}(X_i > 0), \qquad
\text{CR}_B = \frac{1}{n_B} \sum_{i \in B} \mathbb{I}(X_i > 0)
$$
Далее предположим, что мы рассматриваем денежную метрику (выручку, доход и т.д.).
Выручка на пользователя (RPU):
$$
\text{RPU}_A = \frac{1}{n_A} \sum_{i \in A} X_i, \qquad
\text{RPU}_B = \frac{1}{n_B} \sum_{i \in B} X_i
$$
Выручка на платящего пользователя (RPPU)
Выручка на Платящего Пользователя (RPPU) определяется как средняя выручка, полученная от пользователей, совершивших хотя бы одну покупку (т.е. платящих пользователей) в группе: $$ \text{RPPU}_A = \frac{\sum_{i \in A} X_i \cdot \mathbb{I}(X_i > 0)}{\sum_{i \in A} \mathbb{I}(X_i > 0)} \\ \\ \text{RPPU}_B = \frac{\sum_{i \in B} X_i \cdot \mathbb{I}(X_i > 0)}{\sum_{i \in B} \mathbb{I}(X_i > 0)} $$
где $\mathbb{I}(X_i > 0)$ — это индикаторная функция, равная 1, если пользователь $i$ совершил покупку, и 0 в противном случае. RPPU измеряет среднюю выручку по пользователям, которые действительно заплатили, предоставляя информацию о поведении платящих пользователей, независимо от конверсии (CR).
Ключевые факторы модели
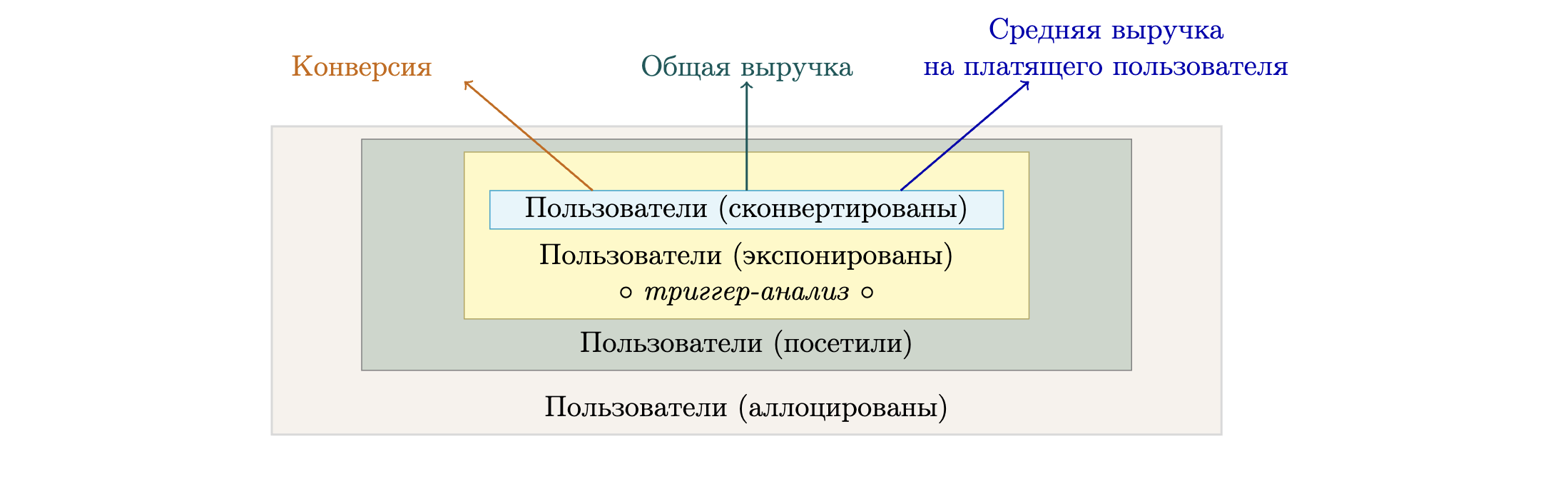
Эта модель различает аллоцированных по группам A и B пользователей и экспонированных пользователей, т.е. тех, кто реально участвовал в эксперименте (например, увидел вариант или контроль). Включение в расчёт только экспонированных пользователей гарантирует, что все результаты отражают реальное воздействие эксперимента.
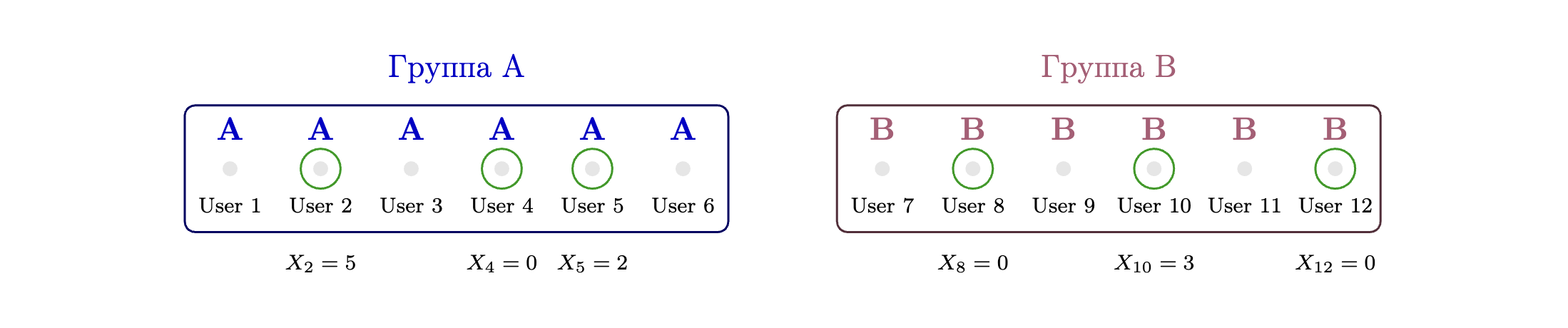
Пользователи сначала распределяются по группам (A или B), но только часть из них реально попадает в эксперимент (обведены зелёным). Метрики считаются только для таких экспонированных пользователей, это обеспечивает корректность анализа. Некоторые пользователи имеют $X_i = 0$, что означает отсутствие конверсии и учитывается при расчёте конверсионных метрик. Такая модель обеспечивает более точную оценку эффекта и поддерживает строгий статистический анализ.
Этот подход подразумевает триггер-анализ, который и повышает точность статистической оценки, выделяя пользователей, которые действительно взаимодействовали с фичей (в варианте A и B).
Однако следует помнить, что поскольку метрики рассчитываются только для таких пользователей, которые реально взаимодействовали с изменением, наблюдаемый эффект будет отличаться от эффекта всей популяции. Это важно учитывать при интерпретации результатов.
Если $\Delta_{Tr}$ — несмещённая оценка эффекта на триггерную популяцию (т.е. для пользователей попавших в эксперимент), как получить оценку эффекта для всей популяции? Часто при user-level триггер-анализе используется следующая формула:
$$ \Delta_{overall} = \Delta_{Tr} \times \frac{N_{Tr}}{N}, $$
где $\Delta_{overall}$ — это оценка эффекта на всю популяцию, $N_{Tr}$ и $N$ — количество пользователей в триггер-анализе и во всей популяции соответственно.
Суммарные метрики и средние метрики
Для стейкхолдеров суммарные метрики, такие как общее количество продаж, общая выручка, общее количество скачиваний, часто проще для понимания при рассмотрении результатов A/B теста. Однако, насколько допустимо тестировать и оценивать такие суммы? Здесь есть несколько проблемных моментов. Во-первых, двухвыборочный t-тест предназначен для сравнения средних двух популяций, а не сумм. Если интересует относительный прирост, и размеры выборок в группах совпадают, тестирование средних эквивалентно тестированию сумм. Но на практике размеры групп редко совпадают. Если логируются только экспонированные пользователи, невозможно гарантировать равные размеры. В таких случаях опасно сравнивать ненормированные метрики, так как неравенство размеров может исказить выводы. Вторая проблема связана с оценкой дисперсии при анализе абсолютного прироста. Для каждой группы дисперсия суммы, при i.i.d. это:
$$ \text{var}(\sum_{i=1}^{n} X_i) = n\sigma^2 $$
Она растёт с увеличением размера. Дисперсия для среднего:
$$ \text{var}(\bar X) = \sigma^2/ n $$
Она уменьшается с увеличением размера.
Однако, следует отметить, что правильная бакетизация (см. ниже) может нивелировать данную проблему, так как за счет рандомного равномерного распределения пользователей по группам она уменьшает влияние дисперсии на результаты. Но по прежнему остается проблема перекоса в размерах групп, которая может исказить выводы. Поэтому рекомендуется использовать нормированные метрики, например, выручку на платящего пользователя (RPPU), которые учитывают размер группы и обеспечивают более корректное сравнение.
Декомпозиция общей выручки: RPPU и конверсия
Важный момент AB-тестирования — декомпозиция общей выручки и соответственно выручки на пользователя (RPU) на две интерпретируемые и статистически понятные компоненты:
- конверсия (CR)
- выручка на платящего пользователя (RPPU)
Любое изменение общей выручки можно объяснить изменением конверсии, RPPU или обоими составляющими сразу. Например:
| Сумма | Средне (RPPU) | Users converted | Интерпретация |
|---|---|---|---|
| ↑ | ↑ | = | Сумма изменилась за счет эффекта в средних (Avg) |
| ↑ | = | ↑ | Сумма изменилась за счет эффекта в Users converted (т.е. выше CR - больше пользователей конвертировалось) |
| = | ↓ | ↑ | В сумме нет изменения, но есть некий эффект в ее составляющих |
| ↑ | ↓ | ↑ | Сумма выросла за счет увеличения числа конвертированных пользователей, несмотря на снижение средних (Avg) |
Математическая декомпозиция: $$ \text{Revenue per User (RPU)} = \text{RPPU} \times \text{CR} $$
Эта декомпозиция особенно полезна для анализа влияния изменений продукта или маркетинговых активностей на оба компонента результата. Понимание этих составляющих помогает принимать более обоснованные решения. RPU показывает, сколько в среднем платят пользователи платформы, а CR — долю пользователей, которые совершают покупку. Вместе они дают полное представление о выручке на пользователя, что в полной мере соответствует задачам unit-экономики и позволяет более точно оценивать влияние изменений на бизнес.
Нелинейные метрики и ratio-метрики
Нелинейные метрики — это метрики, которые не обладают свойством линейности. Метрика называется линейной, если она удовлетворяет следующему свойству:
Для любых выборок $A = {a_1, a_2, \ldots, a_n}$ и $B = {b_1, b_2, \ldots, b_n}$ одинакового размера, и любых коэффициентов $\alpha, \beta \in \mathbb{R}$, значение метрики для поэлементной линейной комбинации равно линейной комбинации значений метрик:
$$ M({\alpha a_1 + \beta b_1, \alpha a_2 + \beta b_2, \ldots, \alpha a_n + \beta b_n}) = \alpha M(A) + \beta M(B) $$
Это свойство выполняется для арифметического среднего:
$$ \text{среднее}(\alpha A + \beta B) = \alpha \cdot \text{среднее}(A) + \beta \cdot \text{среднее}(B) $$
Однако это свойство не выполняется для медианы, персентилей, моды и т.д. Например,
$$ \text{медиана}(\alpha A + \beta B) \neq \alpha \cdot \text{медиана}(A) + \beta \cdot \text{медиана}(B) \; \text{(в общем случае)} $$
Для оценки значимости изменений в нелинейных метриках можно применять следующие подходы:
- Асимптотические методы — например, Тест Бонетта-Прайса (асимптотически нормальный) для медиан, который позволяет получить приближённую оценку стандартной ошибки медианы при больших выборках.
- Бутстрап методы — например, Пуассоновский бутстрап для персентилей, который использует биномиальное приближение для оценки доверительных интервалов и дисперсии.
Ratio-метрики — это метрики, которые представляют собой отношение двух случайных величин, например, CTR (Click-Through Rate), AOV (Average Order Value).
$$ \text{CTR} = \frac{\text{Клики}}{\text{Показы}}; \qquad \text{AOV (средний чек)} = \frac{\text{Общая выручка}}{\text{Количество заказов}} $$
Для ratio-метрик стандартная дисперсия не вычисляется напрямую, поскольку числитель и знаменатель могут быть скоррелированы. В таких случаях можно применять дельта-метод — асимптотический подход для приближённой оценки дисперсии ratio-метрик:
$$ \mathrm{Var}\left(\frac{X}{Y}\right) \approx \frac{1}{\mathbb{E}[Y]^2} \mathrm{Var}(X) + \frac{\mathbb{E}[X]^2}{\mathbb{E}[Y]^4} \mathrm{Var}(Y) - 2\frac{\mathbb{E}[X]}{\mathbb{E}[Y]^3} \mathrm{Cov}(X, Y) $$
Дельта-метод позволяет строить доверительные интервалы для ratio-метрик корректным образом и соответственно проводить для этих метрик статистические тесты.
Проверка SRM (Sample Ratio Mismatch - несоответствие соотношения выборок)
Для корректного вывода необходимо проверять SRM среди экспонированных пользователей: $$ SRM = true/false $$ в зависимости от того, соответствует ли наблюдаемое распределение $n_{exp,A}$ и $n_{exp,B}$ пользователей по группам ожидаемой пропорции.
Решение проблемы большого множества метрик
В крупных платформах AB-тестирования с тысячами метрик (например, 5000+) анализ становится вычислительно сложным и статистически проблемным из-за множественных сравнений. Для решения этих задач можно использовать следующие стратегии:
- North Star Metric: Выделить одну ключевую метрику, отражающую главную бизнес-цель.
- Success-Guardrail Framework: Использовать одну метрику успеха для принятия решений и несколько защитных метрик для мониторинга побочных эффектов.
- Составные метрики: Объединять несколько связанных метрик в один показатель, снижая тем самым количество метрик, но сохраняя важную информацию.
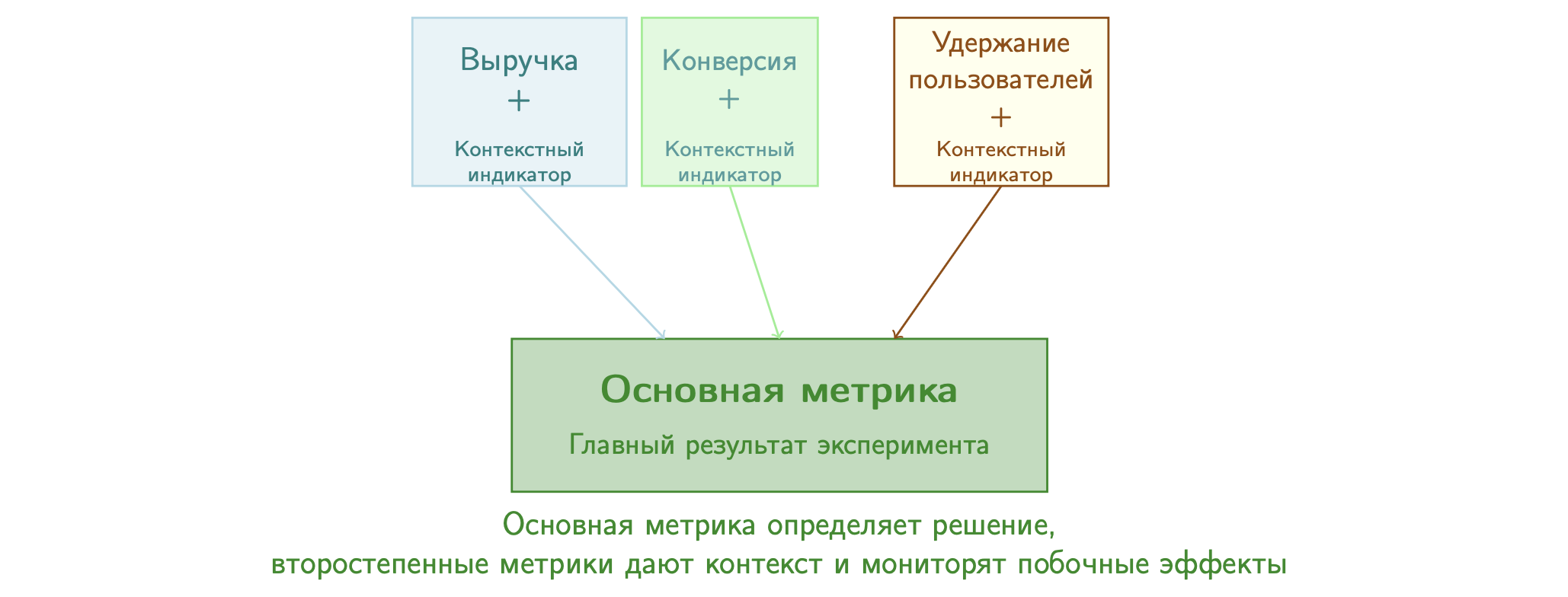
- Разделение на основные и второстепенные метрики: Чётко различать основные метрики (главный результат) и второстепенные (дополнительные индикаторы).
Стратегия 1: Выделение ключевой метрики (North Star Metric)
Ключевая метрика (NSM) — это основная единственная метрика, которая отражает главную эффективность сервиса. Она должна соответствовать долгосрочным целям бизнеса и непосредственно зависеть от изменений продукта. Например, для платформы электронной коммерции NSM может быть "Ежемесячные активные покупатели" или "Средний доход на пользователя".
Эта метрика может служить основным критерием для принятия решений в AB-тестах.
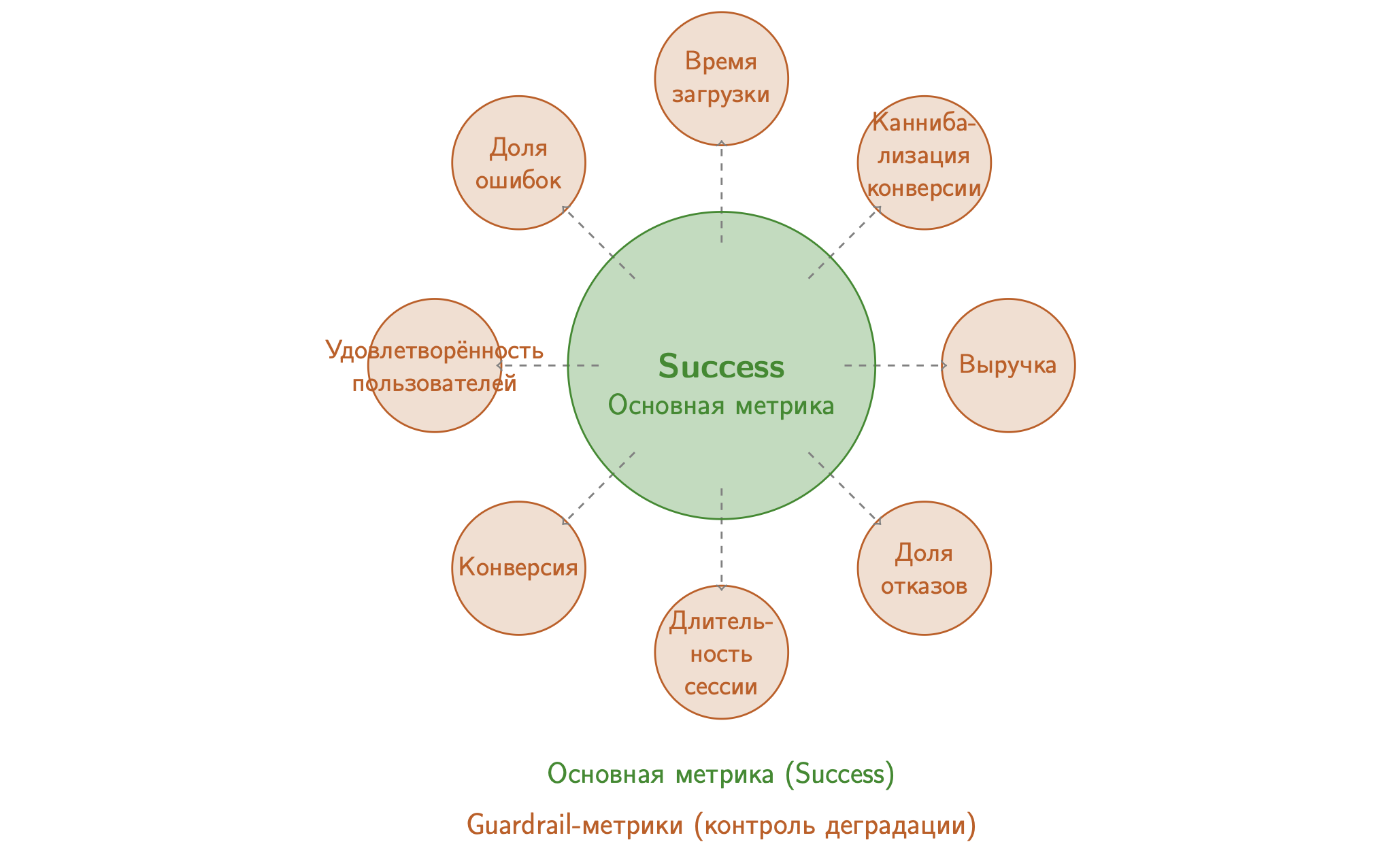
Стратегия 2: Метрика успеха плюс защитные метрики (Success-Guardrail Framework)
Подход позволяет принимать решение на основе одной основной метрики успеха с мониторингом потенциальных побочных эффектов с помощью дополнительных метрик. Защитные метрики обеспечивают отсутствие негативного влияния на важные аспекты пользовательского опыта.
Стратегия 3: Составные метрики (Overall Evaluation Criteria)
Составные метрики объединяют несколько связанных метрик в один показатель, снижая количество тестируемых метрик, но сохраняя важную информацию. Например, составная метрика может быть определена как: $$ OEC = \sum_{i=1}^n w_i \cdot \text{normalize}(m_i) $$
Где: $$ \begin{align} & \sum_{i=1}^n w_i = 1 \quad \text{(веса, в сумме равны 1)} \\ & \text{при условии} \quad m_j \geq \text{threshold}_j \quad \forall j \in \text{critical_metrics} \end{align} $$
Веса отражают важность каждой метрики. Этот подход позволяет более целостно оценивать результаты тестов, не перегружая заинтересованные стороны множеством отдельных метрик.

Стратегия 4: Определение основных и второстепенных метрик
Чёткое различие основных метрик (главный результат) и второстепенных метрик (дополнительные индикаторы) помогает сосредоточить анализ на самых критических выводах, одновременно контролируя другие релевантные метрики.
Статистические критерии и Бакетизация
Для расчета большого количества A/B тестов необходимо применять статистические подходы, которые обладают достаточной универсальностью. Решение должно быть достаточно строгим, чтобы обеспечить статистическую валидность результатов, но при этом достаточно гибким для работы с большим количеством метрик и экспериментов. Оно должно уметь:
- Статистическая значимость: Использовать подходящие стат-критерии для оценки значимости различий между группами.
- Оценка эффекта: Рассчитывать размер эффекта для количественной оценки различий.
- Доверительные интервалы: Предоставлять интервалы для ключевых метрик, чтобы показать неопределённость оценок.
- Расчёт размера выборки: Определять минимальный размер выборки для достижения нужной мощности и уровня значимости.
- MDE: Рассчитывать минимально обнаруживаемый эффект (MDE).
- Коррекция на множественные сравнения: Применять корректировки при анализе множества метрик.
- Рандомизация: Обеспечивать сплитование с выбранными параметрами. Консистентность детерминистической хэш-функции. Возможность запускать, как пересекающиеся (ортогонально), так и не пересекающиеся эксперименты.
- Проверка SRM: Убедиться, что фактические размеры групп соответствуют ожидаемому распределению.
Бакетизация — это статистический подход для больших данных, реализующий группировку пользователей по бакетам. Она позволяет структурировать анализ и применять статистические тесты для разных экспериментов и метрик. При этом важно правильно реализовать бакетизацию, чтобы избежать погрешностей и обеспечить корректные сравнения, в частности учитывать следующие аспекты:
- Граница применимости: Бакетизация применима только при достаточно больших данных для осмысленной группировки. Для малых данных она не подходит.
- Побакетная рандомизация: Процесс бакетизации должен быть случайным, чтобы каждый бакет был репрезентативен.
- Число бакетов: Число бакетов выбирается исходя из размера данных и вариабельности метрик. Обычно используют фиксированное число, но оно может варьироваться в зависимости от задачи (например, 100, 250, 500).
Бакетизация плюс предложенные стратегии для выбора и управления множественными метриками должны улучшить процесс анализа результатов A/B тестов, обеспечивая при этом достаточный статистический контроль и интерпретируемость результатов.
Заключение
В этом документе изложена математическая основа AB-тестирования для больших данных и множества метрик, акцентируя важность чётких определений, строгого статистического анализа и использования нескольких метрик для отражения сложности современных экспериментов.
Практические рекомендации:
- Всегда анализируйте и интерпретируйте, как выручку на пользователя, так и конверсионные метрики, декомпозируя эффекты, это необходимо для понимания того, за счёт чего произошли изменения.
- Помните о том, что не нормализованные метрики (суммы) могут привести к искажению выводов, когда количество попавших случайным образом пользователей в группы A и B будет заметно отличаться. Поэтому лучше использовать усредненные нормализованные метрики.
- Определите зону применимости бакетизации, не используйте ее для "малых'" метрик.
- Для медианы и персентилей используйте непараметрические или асимптотические критерии (например, бутстрэп, Benett-Price).
- Помните, о том, что медиана в случае денежных метрик не является репрезентативным для бизнеса показателем.
- Для ratio-метрик (CTR, AOV) можно применять дельта-метод для оценки дисперсии и доверительных интервалов.
Бакетизация плюс предложенные стратегии для выбора и управления множественными метриками должны улучшить процесс анализа результатов A/B тестов, обеспечивая при этом достаточный статистический контроль и интерпретируемость результатов.
Создавая прочную основу для AB-тестирования, мы обеспечиваем воспроизводимость, сопоставимость и статистическую валидность результатов, что ведёт к лучшим решениям и более эффективным экспериментам.