ClickHouse на Windows 10 & Jupyter Notebook для анализа данных Logs API
Опубликовано: 10 мар 2019
Данная статья возникла, как результат желания протестировать функционал ClickHouse на простом привычном окружении. Поскольку я в основном использую Windows 10, в которой имеется возможность подключить компонент Windows Subsystem for Linux, эта операционная система и была выбрана для развертывания ClickHouse. Фактически все описанное здесь было выполнено на самом простом домашнем ноутбуке.
Поскольку я не являюсь экспертом Linux, я искал такой вариант развертывания, который можно было бы осуществить просто следуя небольшому набору команд. Пришлось протестировать несколько вариантов, и так как в некоторых случаях возникали ошибки, с которыми не очень хотелось разбираться, я выбрал тот дистрибутив, в котором все прошло наиболее гладко. Таким дистрибутивом оказалась Ubuntu 16.04, пакет которой для WSL можно скачать на странице Manually download Windows Subsystem for Linux.
Установка Ubuntu
Прежде чем устанавливать Ubuntu нужно активировать компонент Windows Subsystem for Linux в Windows 10. Для этого, нажав клавиши Win + R нужно запустить команду appwiz.cpl, затем в открывшемся окне перейти на вкладку "Включение и отключение компонентов Windows" и поставить галочку на против нужного компонента:
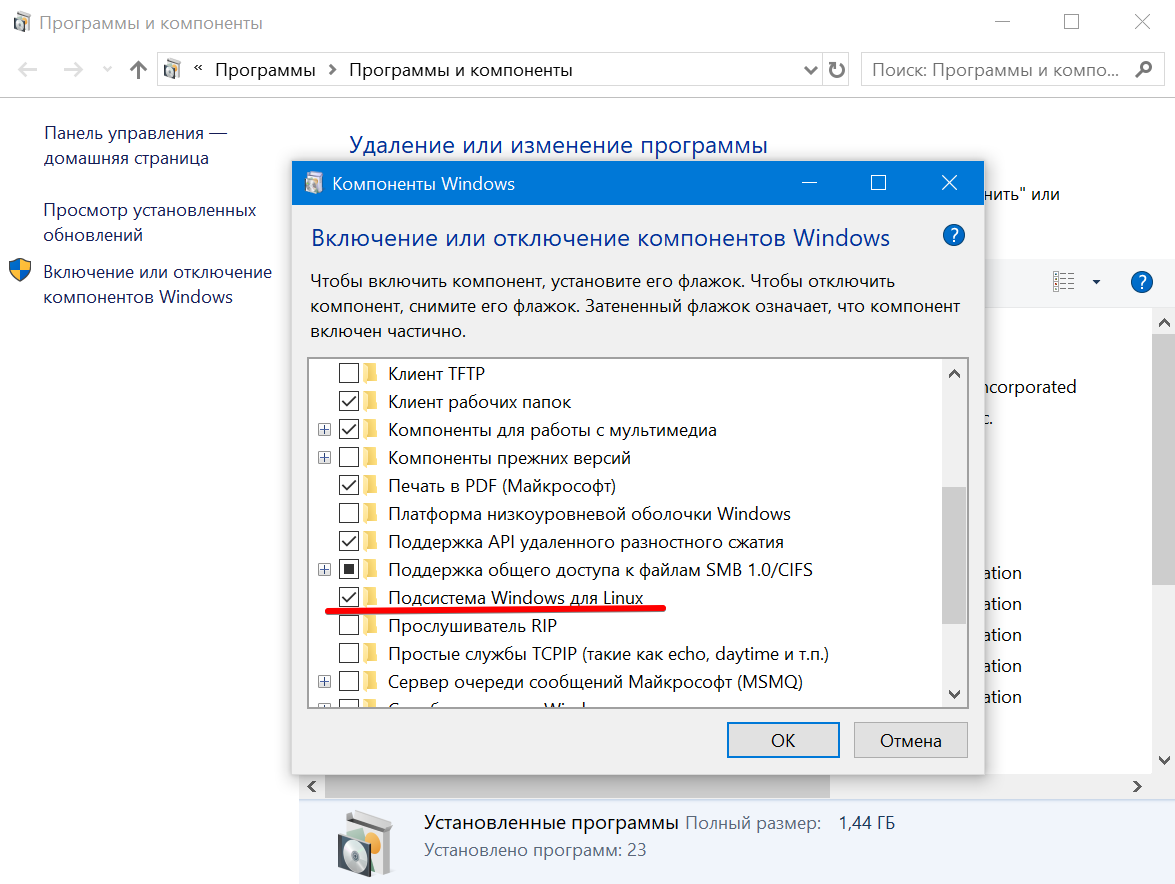
Развертывание ClickHouse
После установки Ubuntu на наш ноутбук с Windows 10 можно приступить к установке ClickHause. Cледуя шагам, предложенным в инструкции от Яндекса, выполним ряд соответствующих команд в терминале Ubuntu:
1. Добавляем репозиторий яндекса в список репозиториев
sudo sh -c "echo deb http://repo.yandex.ru/clickhouse/deb/stable/ main/ >> /etc/apt/sources.list"
2. Добавляем ключ авторизации пакета
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv E0C56BD4
3. Устанавливаем пакет ClickHouse, состоящий из сервера и клиента
sudo apt-get update
sudo apt-get install clickhouse-client clickhouse-server
4. Поскольку мы разворачиваем ClickHouse на локальной машине, мы можем дать ему расширенные права доступа к соответсвующим директориям, что упростит процесс установки.
sudo chmod 777 /var/lib/clickhouse/
sudo chmod 777 /var/log/clickhouse-server/
sudo chown -R clickhouse:clickhouse /var/log/clickhouse-server/
sudo chown -R clickhouse:clickhouse /var/lib/clickhouse
5. По ходу установки выяснилось, что дополнительно нужно сконфигурировать в развернутой Ubuntu региональную временную зону
sudo dpkg-reconfigure tzdata
6. Теперь мы можем проверить готов ли к работе развернутый clickhouse-server, запустив его в режиме логирования в окно терминала:
clickhouse-server --config-file=/etc/clickhouse-server/config.xml
На экране появится много информационных сообщений, из которых нам по сути важно только поддтверждение запуска сервера и слушания приложением портов localhost:
Application: Listening http://127.0.0.1:8123
Ubuntu напрямую коммуницирует с localhost в Windows, что естественно очень удобно, и что позволяет работать с ClickHouse непосредственно из браузера в Windows, в том числе в Jupyter Notebook.
7. Если все установилось, запускаем сервер и клиент ClickHouse:
sudo service clickhouse-server start --config-file=/etc/clickhouse-server/config.xml
clickhouse-client
Увидев приглашение от clickhouse-client, вы можете отправить тестовый запрос:
ClickHouse client version 0.0.18749.
Connecting to localhost:9000.
Connected to ClickHouse server version 0.0.18749.
:) SELECT 1
┌─1─┐
│ 1 │
└───┘
1 rows in set. Elapsed: 0.003 sec.
Параметр config-file в большинстве случаев можно опустить. Эти две команды и будут в дальнейшем использоваться для запуска ClickHouse:
sudo service clickhouse-server start
clickhouse-client
Доступ по API к отчетам Яндекс Метрики и к Logs API
Чтобы иметь возможность обращаться по API к данным отчетов метрики и к данным хитов в Logs API нужно выполнить несколько несложных действий, следуя инструкциям от Яндекса:
По сути все сводится к регистрации условного приложения и получения для него токена для авторизации в вышеперечисленных API. Наиболее простой способ для начала работы - это получить отладочный токен, который действует достаточно долго, затем его можно будет обновить.
Работа с ClickHouse и Logs API в Jupyter Notebook
Благодаря сообществу пользователей ClickHouse появились ряд визуальных интерфейсов и библиотек, упрощающих взаимодействие с инструментом. Данная же статья будет следовать примерам, которые демонстрировали сами специалисты Яндекса на проводимых ими лекциях и вебинарах.
Открываем Jupyter Notebook и первым делом загружаем ряд необходимых пакетов:
import requests
import sys
from datetime import date
from datetime import timedelta
import urllib
Мы можем сохранить выданный нашему приложению авторизационный токен в файл и прочитать его с помощью команды:
with open('token.txt') as f:
TOKEN = f.read().strip()
В качетсве димонстрации вот пример обращения к API отчетов метрики, где мы берем некоторые данные за вчерашний день:
header = {'Authorization': 'OAuth '+TOKEN}
ids = 11113333
payload = {
'metrics': 'ym:s:pageviews, ym:s:users',
'date1': (date.today() - timedelta(days=1)).isoformat(),
'date2': (date.today() - timedelta(days=1)).isoformat(),
'ids': ids,
'accuracy': 'full',
'pretty': True,
}
r = requests.get('https://api-metrika.yandex.ru/stat/v1/data', params=payload, headers=header).content
import json
print (json.dumps(json.loads(r)['data'], indent = 2))
При обращение же к Logs API вначале нам нужно проверить возможность формирования данных. Зададим параметры: мы обращаемся к хитам, а не к визитам и берем данные за вчерашний день. Отправим соответствующий запрос:
API_HOST = 'https://api-metrika.yandex.ru'
COUNTER_ID = 11113333
START_DATE = (date.today() - timedelta(days=1)).isoformat()
END_DATE = (date.today() - timedelta(days=1)).isoformat()
SOURCE = 'hits'
API_FIELDS = ('ym:pv:date', 'ym:pv:dateTime', 'ym:pv:URL', 'ym:pv:deviceCategory',
'ym:pv:operatingSystemRoot', 'ym:pv:clientID', 'ym:pv:browser', 'ym:pv:lastTrafficSource')
url_params = urllib.urlencode(
[
('date1', START_DATE),
('date2', END_DATE),
('source', SOURCE),
('fields', ','.join(API_FIELDS))
]
)
url = 'https://api-metrika.yandex.ru/management/v1/counter/11113333/logrequests/evaluate?'\
.format(host=API_HOST, counter_id=COUNTER_ID) + url_params
r = requests.get(url, headers={'Authorization': 'OAuth '+TOKEN})
r.status_code
Код 200 означает, что запрос отправлен успешно. А вот ответ о возможности получить данные:
json.loads(r.text)['log_request_evaluation']
Как видно, в случае данного сайта есть возможность получить одним запросом данные за 341 день. Теперь отправим запрос непосредственно на получение данных:
url_params = urllib.urlencode(
[
('date1', START_DATE),
('date2', END_DATE),
('source', SOURCE),
('fields', ','.join(sorted(API_FIELDS, key=lambda s: s.lower())))
]
)
url = '{host}/management/v1/counter/{counter_id}/logrequests?'\
.format(host=API_HOST,
counter_id=COUNTER_ID) \
+ url_params
r = requests.post(url, headers={'Authorization': 'OAuth '+TOKEN})
r.status_code
print (json.dumps(json.loads(r.text)['log_request'], indent = 2))
Поскольку данные могут формироваться некоторое время из этих данных нам потребуется request_id для проверки готовности ответа.
request_id = json.loads(r.text)['log_request']['request_id']
Задаем параметры и проверяем готовность ответа:
url = '{host}/management/v1/counter/{counter_id}/logrequest/{request_id}' \
.format(request_id=request_id,
counter_id=COUNTER_ID,
host=API_HOST)
r = requests.get(url, params="", headers=header)
r.status_code
print (json.dumps(json.loads(r.text)['log_request'], indent = 4))
Если видим статус "created" - ждем, если статус "processed", это означает, что данные готовы, и что ответ будет состоять из какого-то количества частей.
parts = json.loads(r.text)['log_request']['parts']
print(parts)
Получаем ответ и помещаем его в Pandas DataFrame
import io
import StringIO
import pandas as pd
tmp_dfs = []
for part_num in map(lambda x: x['part_number'], parts):
url = '{host}/management/v1/counter/{counter_id}/logrequest/{request_id}/part/{part}/download' \
.format(
host=API_HOST,
counter_id=COUNTER_ID,
request_id=request_id,
part=part_num
)
r = requests.get(url, headers=header)
if r.status_code == 200:
tmp_df = pd.read_csv(io.StringIO(r.text), sep = '\t')
tmp_dfs.append(tmp_df)
else:
raise ValueError(r.text)
df = pd.concat(tmp_dfs)
df.shape
Мы можем сохранить полученные данные в csv файл, если в дальнейшем они нам могут понадобится
df.to_csv('site_data.csv', sep = '\t', index = False, encoding='utf-8', line_terminator='\n')
Один из параметров, которые нужны для взаимодействия с ClickHouse через браузер это хост:
HOST = 'http://localhost:8123'
Так, к примеру, если вы зайдете на http://localhost:9000 то можно прочесть:
Port 9000 is for clickhouse-client program.
You must use port 8123 for HTTP.
Определим функции для работы с ClickHouse из нашего Jupyter Notebook. Функции повторяют примеры, размещенные на вебинарах Яндекса1:
def get_clickhouse_data(query, host = HOST, connection_timeout = 1500):
r = requests.post(host, params = {'query': query}, timeout = connection_timeout)
if r.status_code == 200:
return r.text
else:
raise ValueError(r.text)
def get_clickhouse_df(query, host = HOST, connection_timeout = 1500):
data = get_clickhouse_data(query, host, connection_timeout)
df = pd.read_csv(StringIO.StringIO(data), sep = '\t')
return df
def upload(table, content, host=HOST):
# content = content.encode('utf-8')
query_dict = {
'query': 'INSERT INTO ' + table + ' FORMAT TabSeparatedWithNames '
}
r = requests.post(host, data=content, params=query_dict)
result = r.text
if r.status_code == 200:
return result
else:
raise ValueError(r.text)
С чегобы начать? Давайте, например, посмотрим что за базы данных в ClickHouse есть в текущеий момент:
q = '''
SHOW DATABASES
'''
get_clickhouse_df(q)
Поскольку я уже немного поработал с данными, мы видим три базы данных, одна из которых системная. Создадим таблицу в базе funnels, в которую поместим данные из Logs API:
q = 'drop table if exists funnels.visits'
get_clickhouse_data(q)
q = '''
create table funnels.visits (
browser String,
clientID UInt64,
date Date,
dateTime DateTime,
deviceCategory String,
trafficSource String,
system String,
URL String
) ENGINE = MergeTree(date, intHash32(clientID), (date, intHash32(clientID)), 8192)
'''
get_clickhouse_data(q)
Для демонстрации возможности прочтем полученные данные из созданного нами на предыдущих шагах csv файла
df = pd.read_csv('site_data.csv', sep='\t',encoding='utf-8')
df.shape
Загружаем данные в нашу таблицу:
# %%time
upload(
'funnels.visits',
df.to_csv(index = False, sep = '\t', encoding='utf-8',line_terminator='\n'))
Квест пройден, а вот и приз - посмотрим, к примеру, сколько пользователей было вчера на основном разделе нашего сайта:
q = '''
SELECT
uniq(clientID) as users
FROM funnels.visits
WHERE date = yesterday()
AND match(URL,'^https://yoursite.ru/main')
FORMAT TabSeparatedWithNames
'''
get_clickhouse_df(q)
Update
Комментарии от читателейВ статье не указана версия Python (2), для версии 3 код будет немного отличаться - в Python 3 StringIO включен в io модуль: