Аналитический DWH на базе BigQuery
Опубликовано: 08 янв 2019
Аналитическое хранилище данных (DWH) - это возможность анализировать всю цепочку привлечения клиента и продажи услуги или товара вплоть до реальной оплаты. Для создания такой inhouse сквозной аналитики зачастую необходимо данные с разных источников собрать в одном месте, чтобы анализировать их совместно в любых плоскостях.
Веб аналитика, будь то Google Analytics или Яндекс Метрика или любая другая система обладает всеми данными о маркетинговых путях (онлайн реклама) и пользовательских путях (переходы по сайту) посетителей. Сбор таких данных - это то, для чего системы веб аналитики предназначены. Но веб аналитика может не видеть и не знать статус оформленного заказа - бил ли он проплачен, не было ли возврата, не трансформировался ли он в оффлайн покупку и т. п. С другой стороны системы управления заказами и биллинга внутри компании обладают всей информацией о реально оплаченных заказах, но они ничего не знают о пути клиента.
Чтобы создать сквозную аналитику и проанализировать маркетинговые и пользовательские пути в контексте реальных покупок необходимо объединить данные веб аналитики и систем управления заказами.
Ниже представлена верхнеуровневая схема выгрузки данных о фактических продажах в BigQuery в автоматическом режиме для последующего объединения их с данными веб аналитики. Данные же веб аналитики можно передавать в BigQuery с помощью стриминга сырых данных (хитов) Google Analytics в BigQuery в реальном времени. Таким образом мы получим некий маркетинговый DWH для создания сквозной аналитики.
Выгрузка данных в BigQuery в автоматическом режиме для сквозной аналитики
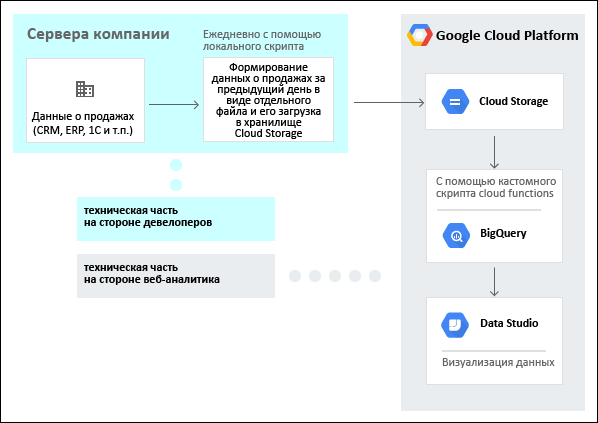
Схема выгружаемых данных и формат файла
Возможны два варианта форматов файла — csv и json и соответственно два типа структуры данных в файле для выгрузки — обычная таблица с повторяющимися Id заказов для каждого товара/сервиса (sku) внутри одного заказа или же денормализованная таблица, в которой данные о каждом заказе хранятся в отдельной json-записи, разделенные новой строчкой.
Google рекомендует в BigQuery использовать денормализованные таблицы с вложенными данными т.е. предпочтительным форматом файла можно считать json.
Пример денормализованных данных одного заказа с несколькими услугами внутри*:
{
"orderId": "3434243",
"userId": "234567",
"date": "2018-12-16",
"revenue": 357.00,
"status": "оплачен полностью",
"purchasedItems": [
{
"sku": "SKU1",
"description": "DESCRIPTION1",
"quantity": 2,
"price": 123.00
},
{
"sku": "SKU2",
"description": "DESCRIPTION2",
"quantity": 5,
"price": 234.00
}
]
}
*Строковые данные оформляются кавычками
Техническая реализация выгрузки файла из локального сервера в Google Cloud Storage
Примеры скриптов для разных языков программирования можно посмотреть здесь, включая реализацию с помощью REST API: Uploading Objects
Авторизация для скрипта загрузки: Cloud Storage Authentication
Важный момент : формат названия выгружаемого файла должен быть строго определен и соответствовать шаблону: orders_20181219.json.
Данный шаблон названия файла - это 3 составляющие:
- общее имя группы файлов, например 'orders'
- нижнее подчеркивание с датой за которую выгружаются данные заказов в формате YYYYMMDD
Дата в названии файла должна соответствовать дате заказов внутри файла.
- расширение файла, например - '.json'
Техническая реализация выгрузки данных файла из Google Cloud Storage в таблицу BigQuery
Веб аналитиком реализуется скрипт, передающий данные из загруженного файла в облачное хранилище (Cloud Storage) по факту его загрузки в соответствующую таблицу проекта в BigQuery с помощью Cloud Functions.
Cloud Storage используется в качестве шага, обеспечивающего сохранность данных и мониторинг загрузок.
Дополнительные ресурсы: Build a Marketing Data Warehouse